

I am a senior AI researcher at a major tech company.
I am also an honorary Research Associate at the University of Bristol.
I was a Postdoctoral Research Associate at the Visual Information Lab (VIL) in Bristol, supervised by Dr Aaron Zhang and Prof. David Bull. My current project, funded by Prime Video, Amazon, focuses on deep video quality assessment.
Prior to this, I was a PhD research student at Machine Learning and Computer Vision Research Group (MaVi) and Visual Information Lab (VIL), University of Bristol, where I was supervised by Dr Alberto Gambaruto and Prof. Tilo Burghardt. We worked on the swallowing project CTAR-SwiFt funded by NIHR.
During my PhD, I spent a great 6 months at Amazon in London as an Applied Scientist, where I worked on developing a cutting-edge camera tracking solution for 8K cameras.
News



Projects
 SAM3-LiteText: An Anatomical Study of the SAM3 Text Encoder for Efficient Vision-Language Segmentation - 2026
SAM3-LiteText: An Anatomical Study of the SAM3 Text Encoder for Efficient Vision-Language Segmentation - 2026
ACM International Conference on Multimedia Retrieval (ICMR 2026), Accepted | Live on 🤗 HuggingFace Transformers main branch
Chengxi Zeng, Yuxuan Jiang, Ge Gao, Shuai Wang, Duolikun Danier, Bin Zhu, Stevan Rudinac, David Bull, Fan Zhang
University of Bristol / Amazon
[Docs] [Model] [Demo] [arXiv]
SAM3-LiteText reduces the SAM3 text encoder by up to 88% while preserving segmentation performance, making the model much smaller without sacrificing accuracy. The work is now live on HuggingFace Transformers main branch, accepted by ICMR 2026, and represents a strong efficiency-first extension to Ultralytics’ existing SAM3 integration.
 BVI-HVS: A Human Visual Perception-Grounded Video Quality Dataset
BVI-HVS: A Human Visual Perception-Grounded Video Quality Dataset
to be Preprint
Chengxi Zeng, Robbie Hamilton, Ge Gao, Yuxuan Jiang, Fan Zhang, Rahul Vanam, Sriram Sethuraman, David Bull
University of Bristol/Amazon
We introduce BVI-HVS, a large-scale VQA dataset grounded in the Human Visual System (HVS) and Contrast Sensitivity Function (CSF). It features 511 curated high-resolution source videos with perceptually-motivated HEVC distortions and patch-level quality labels from a large-scale subjective study. Benchmarking seven VQA models reveals a substantial performance gap, motivating next-generation perceptually-aligned metrics.
 C2D-ISR: Optimizing Attention-based Image Super-resolution from Continuous to Discrete Scales - 2025
C2D-ISR: Optimizing Attention-based Image Super-resolution from Continuous to Discrete Scales - 2025
Preprint, Under Review
Yuxuan Jiang, Chengxi Zeng, Siyue Teng, Fan Zhang, Xiaoqing Zhu, Joel Sole, David Bull
[arXiv]
In recent years, attention mechanisms have been exploited in single image super-resolution (SISR), achieving impressive reconstruction results. However, these advancements are still limited by the reliance on simple training strategies and network architectures designed for discrete up-sampling scales, which hinder the model’s ability to effectively capture information across multiple scales. To address these limitations, we propose a novel framework, C2D-ISR, for optimizing attention-based image super-resolution models from both performance and complexity perspectives. Our approach is based on a two-stage training methodology and a hierarchical encoding mechanism. The new training methodology involves continuous-scale training for discrete scale models, enabling the learning of inter-scale correlations and multi-scale feature representation. In addition, we generalize the hierarchical encoding mechanism with existing attention-based network structures, which can achieve improved spatial feature fusion, cross-scale information aggregation, and more importantly, much faster inference. We have evaluated the C2D-ISR framework based on three efficient attention-based backbones, SwinIR-L, SRFormer-L and MambaIRv2-L, and demonstrated significant improvements over the other existing optimization framework, HiT, in terms of super-resolution performance (up to 0.2dB) and computational complexity reduction (up to 11%).
 Multi-Teacher Knowledge Distillation for Efficient Object Segmentation - 2025
Multi-Teacher Knowledge Distillation for Efficient Object Segmentation - 2025
IEEE International Conference on Image Processing (ICIP 2025), Accepted
Chengxi Simon Zeng, Kurt Cutajar, Hanting Xie, Massimo Camplani, Richard Tomsett, Niall Twomey, Jas Kandola, Gavin K.C. Cheung
Studio AI Lab, Amazon
Segment Anything Model 2 (SAM2) has demonstrated state-of-the-art performance in image/video object segmentation across many domains, but its large encoder makes it challenging for resource-constrained devices or real-time applications. One solution to this problem is to carry out knowledge distillation from the bulky encoder to a lightweight encoder, but this can result in degraded performance. In this work, we investigate multi-teacher distillation to mitigate performance degradation for distilled segmentation models. Using several foundation teacher models, our multi-teacher distilled models achieve 3.2 times speedup during end-to-end inference compared to SAM2 while achieving the best results of 74.4 and 71.1 (72.1 and 69.6 for single-teacher distillation) mIoU on the COCO and LVIS image segmentation datasets, as well as showing competitive results on video segmentation. Our results show that multi-teacher distillation offers a powerful solution for efficient image/video segmentation, while also maintaining compelling performance.
 Agglomerating Large Vision Encoders via Distillation for VFSS Segmentation - 2025
Agglomerating Large Vision Encoders via Distillation for VFSS Segmentation - 2025
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025, Efficient Large Vision Models Workshop (2nd Edition), Accepted
Chengxi Zeng, Yuxuan Jiang, Fan Zhang, Alberto Gambaruto, Tilo Burghardt
[arXiv]
The deployment of foundation models for medical imaging has demonstrated considerable success. However, their training overheads associated with downstream tasks remain substantial due to the size of the image encoders employed, and the inference complexity is also significantly high. Although lightweight variants have been obtained for these foundation models, their performance is constrained by their limited model capacity and suboptimal training strategies. In order to achieve an improved tradeoff between complexity and performance, we propose a new framework to improve the performance of low complexity models via knowledge distillation from multiple large medical foundation models (e.g., MedSAM, R50-DINO, MedCLIP). Each specializing in different vision tasks, with the goal to effectively bridge the performance gap for medical image segmentation tasks. The agglomerated model demonstrates superior generalization across 12 segmentation tasks, whereas specialized models require explicit training for each task. Our approach achieved an average performance gain of 2% in Dice coefficient compared to simple distillation.
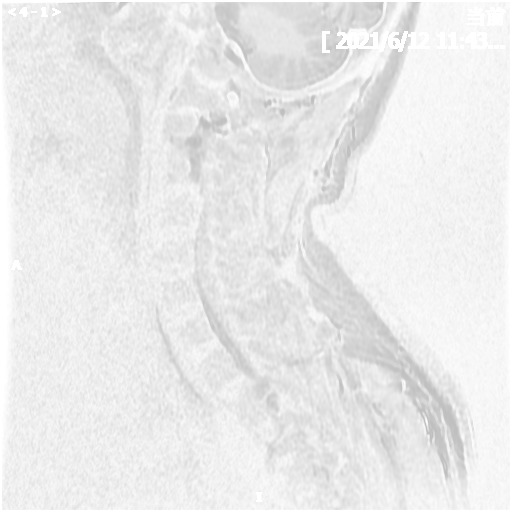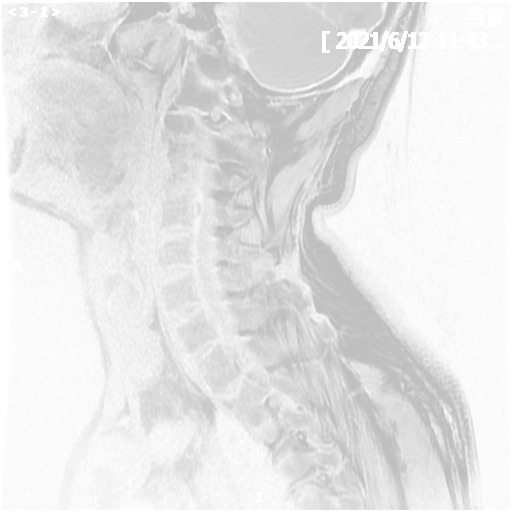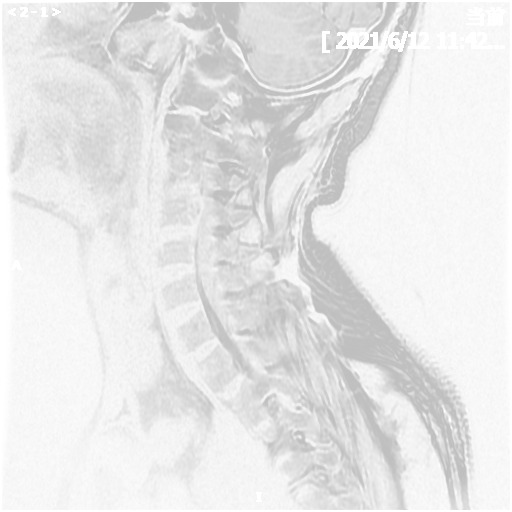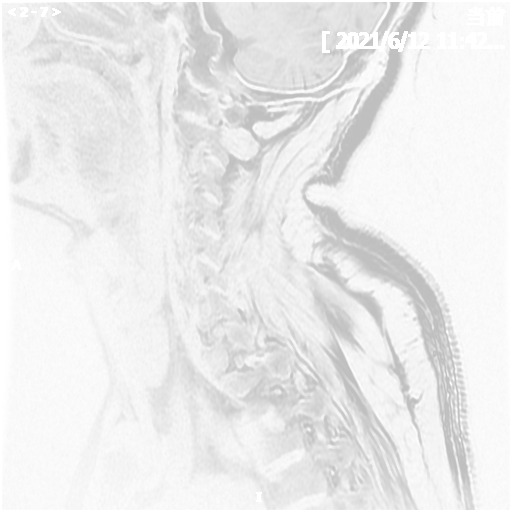 Spinal Cord Injury Detection and Rehabilitation Via Multi-Modal Medical Image Analysis - 2025
Spinal Cord Injury Detection and Rehabilitation Via Multi-Modal Medical Image Analysis - 2025
Ye Tian, Zekai Yang, Chengxi Zeng, Jian Ma
We are developing a multi-modal medical image analysis framework for spinal cord injury detection and are constructing a large-scale dataset of 3D spinal cord segmentations and multi-stage clinical diagnoses from trained doctors. We employ state-of-the-art foundation models to extract features from different modalities and then use a multi-task learning framework to predict injury severity and clinical diagnosis.
 Tuning Vision Foundation Model via Test-Time Prompt-Guided Training for VFSS Segmentations - 2025
Tuning Vision Foundation Model via Test-Time Prompt-Guided Training for VFSS Segmentations - 2025
Preprint, Under Review
Chengxi Zeng, Tilo Burghardt, Alberto Gambaruto
[arXiv]
Vision foundation models have demonstrated exceptional generalization capabilities in segmentation tasks for both generic and specialized images. However, a performance gap persists between foundation models and task-specific, specialized models. Fine-tuning foundation models on downstream datasets is often necessary to bridge this gap. Unfortunately, obtaining fully annotated ground truth for downstream datasets is both challenging and costly. To address this limitation, we propose a novel test-time training paradigm that enhances the performance of foundation models on downstream datasets without requiring full annotations. Specifically, our method employs simple point prompts to guide a test-time semi-self-supervised training task. The model learns by resolving the ambiguity of the point prompt through various augmentations. This approach directly tackles challenges in the medical imaging field, where acquiring annotations is both time-intensive and expensive. We conducted extensive experiments on our new Videofluoroscopy dataset (VFSS-5k) for the instance segmentation task, achieving an average Dice coefficient of 0.868 across 12 anatomies with a single model.
 Tea Classification - 2024
Tea Classification - 2024
Chengxi Zeng, Ted Littledale, Yorkshire Tea (Bettys & Taylors of Harrogate)
[WEB APP]
We developed a tea classification Web App for Yorkshire Tea (Bettys & Taylors of Harrogate). The app is able to classify tea colors from any cups. My main responsibility was to develop image processing code for the tea element and extract the main tone by applying various edge detection and outlier removal techniques. Additionally, I employed the segmentation foundation model Segment Anything on a small tea dataset I created. The model accurately segmented the tea element and was converted to an ONNX file that can be deployed to multiple platforms. Prior to UK national tea day, the app successfully attracted thousands of users in a few weeks.
 RBF-PINN: Non-Fourier Positional Embedding in Physics-Informed Neural Networks - 2024
RBF-PINN: Non-Fourier Positional Embedding in Physics-Informed Neural Networks - 2024
International Conference on Learning Representations (ICLR 2024) , AI4DifferentialEquations in Science Workshop, Accepted
Chengxi Zeng, Tilo Burghardt, Alberto Gambaruto
[Github] [arXiv]
While many recent Physics-Informed Neural Networks (PINNs) variants have had considerable success in solving Partial Differential Equations, the empirical benefits of feature mapping drawn from the broader Neural Representations research have been largely overlooked. We highlight the limitations of widely used Fourier-based feature mapping in certain situations and suggest the use of the conditionally positive definite Radial Basis Function. The empirical findings demonstrate the effectiveness of our approach across a variety of forward and inverse problem cases. Our method can be seamlessly integrated into coordinate-based input neural networks and contribute to the wider field of PINNs research.
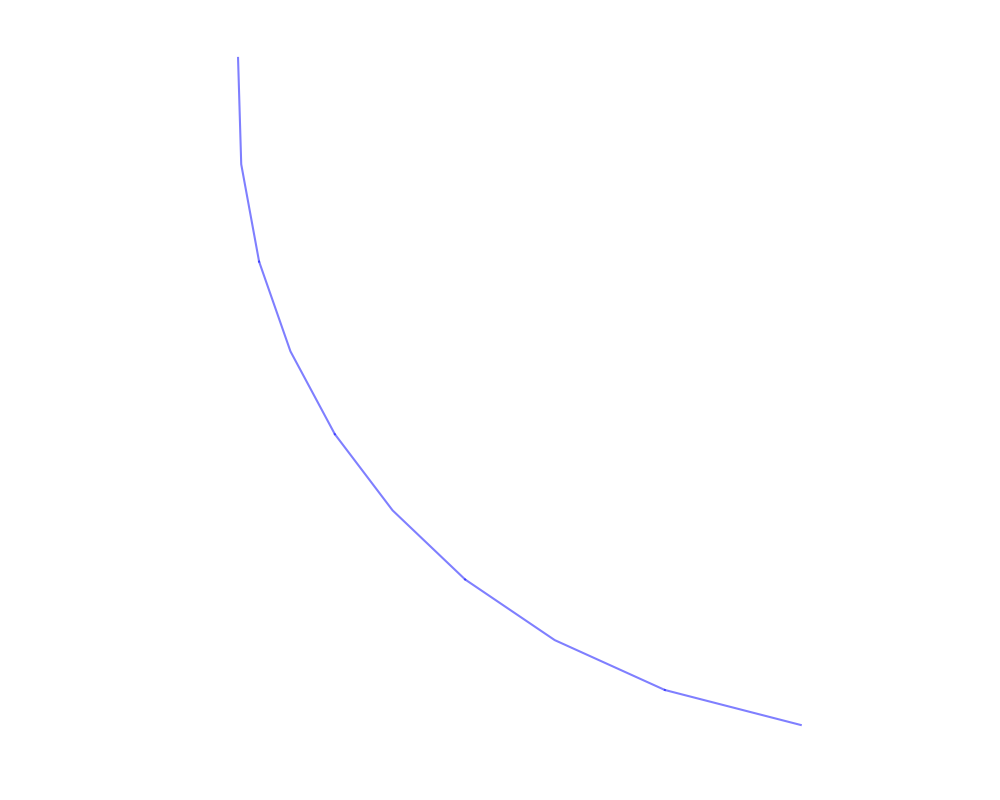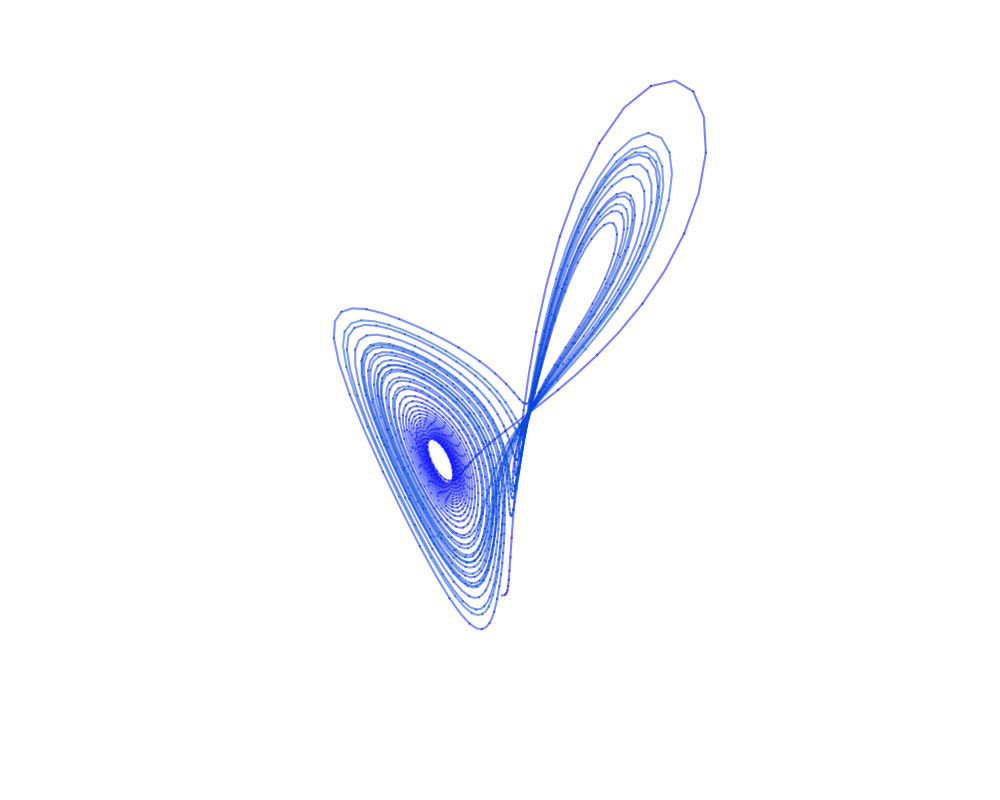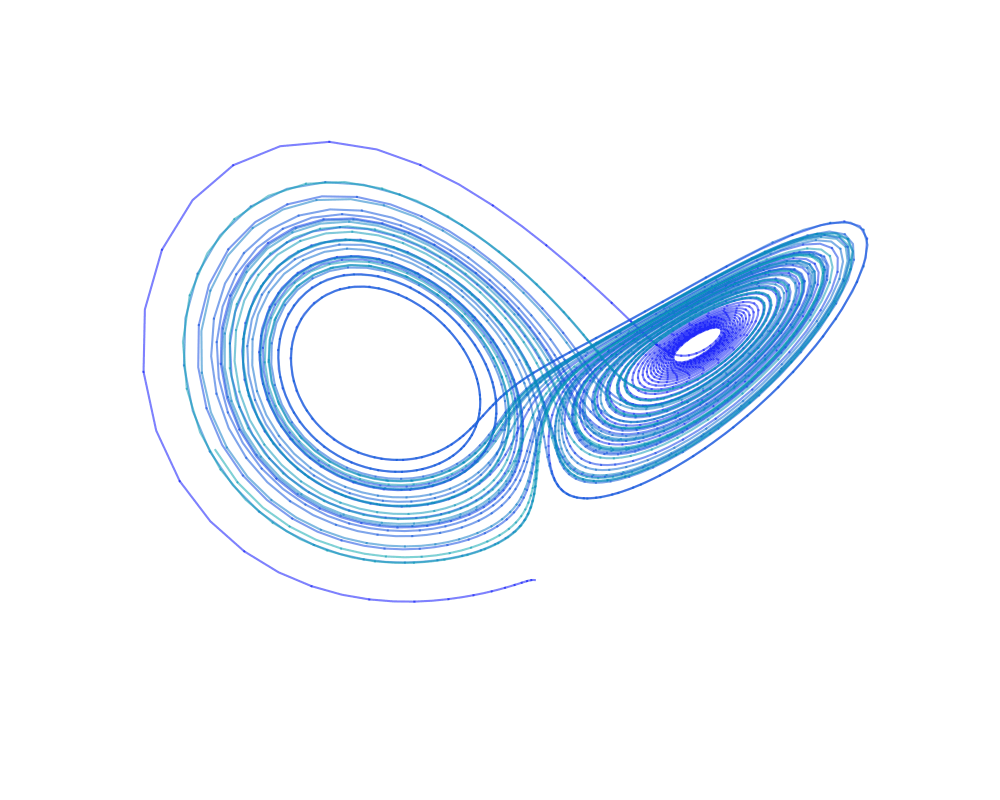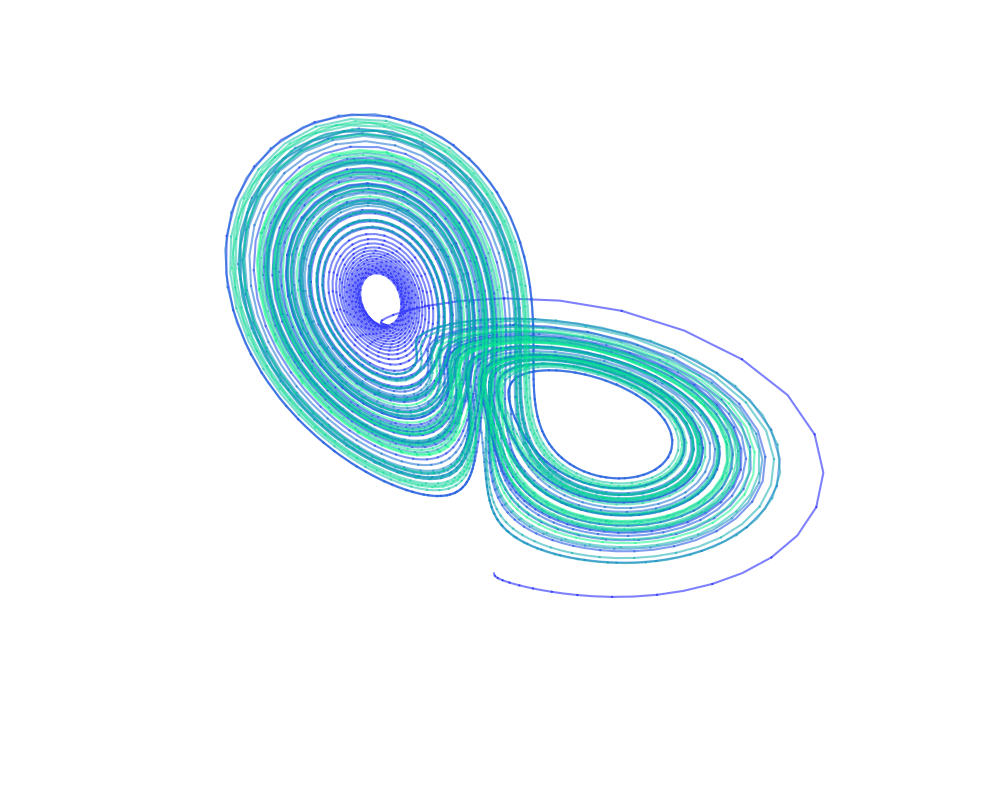 Training dynamics in Physics-Informed Neural Networks with feature mapping - 2024
Training dynamics in Physics-Informed Neural Networks with feature mapping - 2024
Preprint, Under Review
Chengxi Zeng, Tilo Burghardt, Alberto Gambaruto
[Github] [arXiv]
Physics-Informed Neural Networks (PINNs) have emerged as an iconic machine learning approach for solving Partial Differential Equations (PDEs). Although its variants have achieved significant progress, the empirical success of utilising feature mapping from the wider Implicit Neural Representations studies has been substantially neglected. We investigate the training dynamics of PINNs with a feature mapping layer via the limiting Conjugate Kernel and Neural Tangent Kernel, which sheds light on the convergence and generalisation of the model. We also show the inadequacy of commonly used Fourier-based feature mapping in some scenarios and propose the conditional positive definite Radial Basis Function as a better alternative. The empirical results reveal the efficacy of our method in diverse forward and inverse problem sets. This simple technique can be easily implemented in coordinate input networks and benefits the broad PINNs research.
 Video-SwinUNet: Spatio-Temporal deep learning framework for VFSS instance segmentation - 2023
Video-SwinUNet: Spatio-Temporal deep learning framework for VFSS instance segmentation - 2023
IEEE International Conference on Image Processing (ICIP 2023), Accepted
Chengxi Zeng, Xinyu Yang, David Smithard, Majid Mirmehdi, Alberto Gambaruto, Tilo Burghardt
[Github] [arXiv]
This paper presents a deep learning framework for medical video segmentation. Our proposed framework explicitly extracts features from neighbouring frames across the temporal dimension and incorporates them with a novel temporal feature blender which then tokenises the high-level Spatio-temporal feature to a strong global feature encoder Swin Transformer. Our model outperforms other approaches by a significant margin and improves the segmentation benchmarks on the VFSS2022 dataset, achieving a dice coefficient of 0.8986/0.8186 for Part1/Part2 data. Our studies have also shown the efficacy of the temporal feature blending scheme and the transferability of the framework.
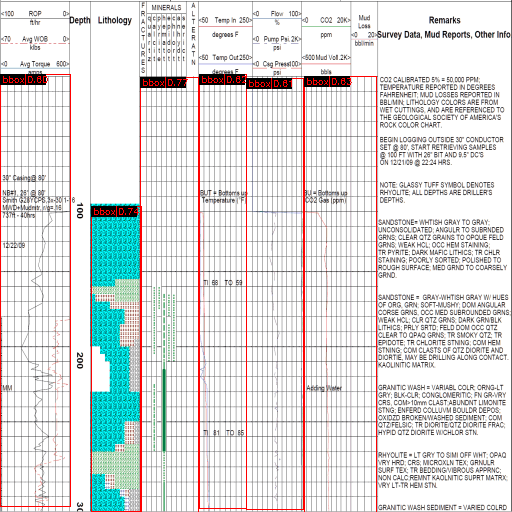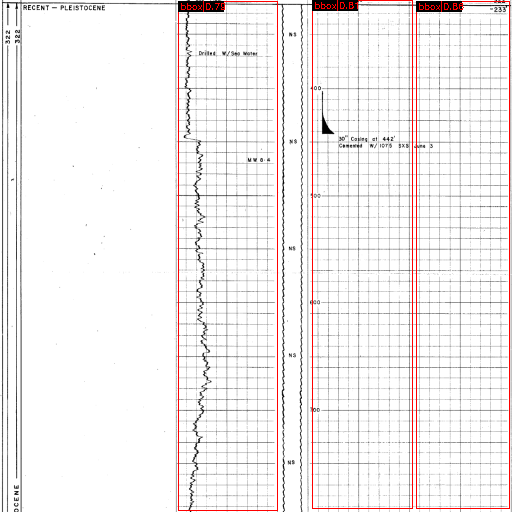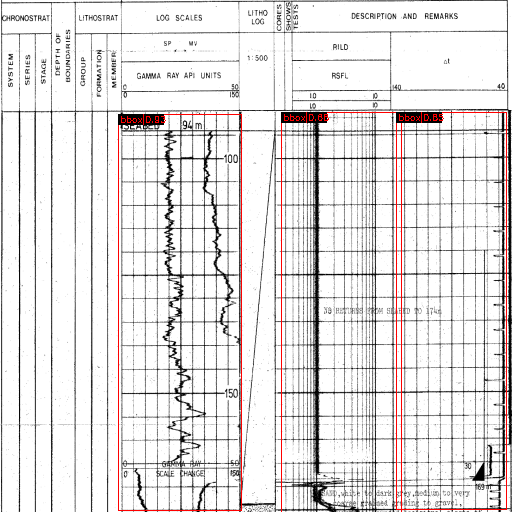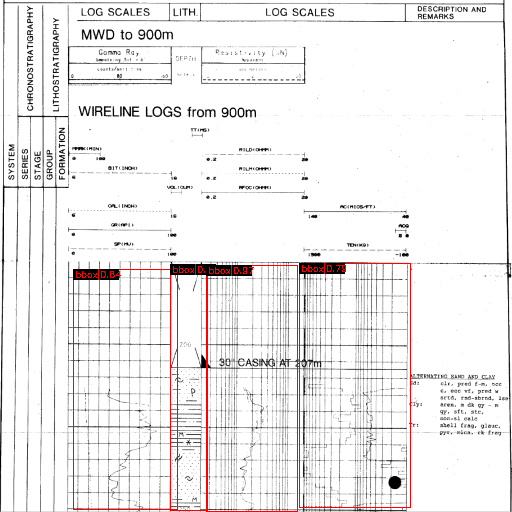 Lithology Document Analysis - 2022
Lithology Document Analysis - 2022
Chengxi Zeng, Arion.ai, CGG
We developed a deep learning pipeline that processes long lithology tracks to multi-page images, a fast bounding box detection algorithm is employed and calibrated. Segmentation models are used to extract the curves and hence the numerical data is restored. The pipeline is tested on 1000+ documents and can process 100+ Page/Sec
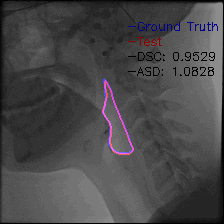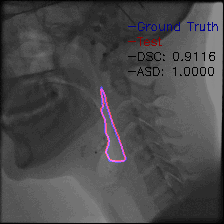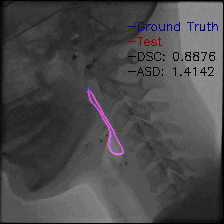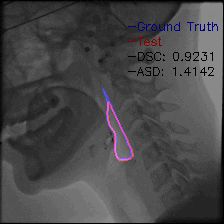 Video-TransUNet: Temporally Blended Vision Transformer for CT VFSS Instance Segmentation - 2022
Video-TransUNet: Temporally Blended Vision Transformer for CT VFSS Instance Segmentation - 2022
SPIE International Conference on Machine Vision (ICMV 2022), Accepted, Best Oral Presentation
Chengxi Zeng, Xinyu Yang, Majid Mirmehdi, Alberto Gambaruto, Tilo Burghardt
[Github] [arXiv]
We propose Video-TransUNet, a deep architecture for instance segmentation in medical CT videos constructed by integrating temporal feature blending into the TransUNet deep learning framework. In particular, our approach amalgamates strong frame representation via a ResNet CNN backbone, multi-frame feature blending via a Temporal Context Module (TCM), non-local attention via a Vision Transformer, and reconstructive capabilities for multiple targets via a UNet-based convolutional-deconvolutional architecture with multiple heads.
{kind=link}
 Portable AED Delivery Emergency Drone (Patented) - 2022
Portable AED Delivery Emergency Drone (Patented) - 2022
Chengxi Zeng, Yuhang Ming, Mengxun Bai, Ruobing Li
We are developing an Emergency drone that delivers medical kits and portable AED which would save lives in jammed cities and remote areas. This project collaborates with Hangzhou Municipal Health Commission and the drone will work with local Emergency Response Unit.
 Elastic Transformation Detection - 2021
Elastic Transformation Detection - 2021
Chengxi Zeng, Haytham Technology Ltd
We utilised CNN and other image processing techniques to non-destructively detect Elastic Transformation on steel/composite materials due to repetitive work load in extreme environments.
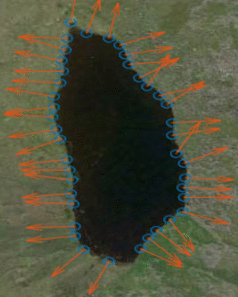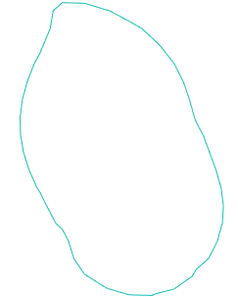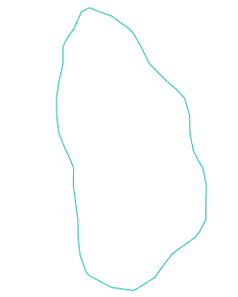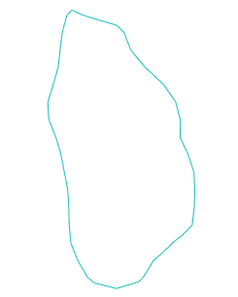 Solving Partial Differential Equations using Radial Basis Functions - 2021
Solving Partial Differential Equations using Radial Basis Functions - 2021
Chengxi Zeng, Andreas Michael, Celia Tugores-Bonilla, Natasha Moore, Jules Boisser, Alberto Gambaruto
We discretise standard Partial Differential Equations(PDEs) using Radial Basis Functions, aiming to assess their performance compared to the analytical results and alternative discretisation methods.
 Pedestrian Level wind assessment with CFD simulation - 2019
Pedestrian Level wind assessment with CFD simulation - 2019
Chengxi Zeng, Alberto Gambaruto
We modelled Bristol city centre area and applied CFD simulation with focus on high wind speed area and presented the advantage of trees to mitigate wind using Porous Media approach.